Elasticsearch Tips & Tracks
Elasticsearch
Elasticsearch是一个开源的分布式搜索与分析引擎,提供近实时搜索和聚合功能
Elastic Stack主要应用于:搜索、日志管理、安全分析、指标分析、业务分析、应用性能监控等多个领域
“Search is something that any application should have.”
Elastic Stack 生态圈
解决方案:
- 搜索
- 日志分析
- 指标分析
- 安全分析
可视化:
- Kibana: 可视化分析
存储/计算:
- Elasticsearch: 核心引擎,提供数据存储、搜索和聚合的能力
数据抓取:
- Logstash
开源的服务器端数据处理管道,支持从不同来源采集数据,转换数据,并将数据发送到不同的存储库中
1
2
3
4
5
6
7
8
9# 特性:
1. 实时解析和转换数据
> 从IP地址破译地理位置
> 从PII数据匿名化,排除敏感字段
2. 可扩展
3. 可靠性安全性
> Logstash 通过持久化队列保证至少将运行中的事件送达一次
> 数据传输加密
4. 加密- Beats
轻量级别数据采集器
- Logstash
X-Pack: 商业化套件
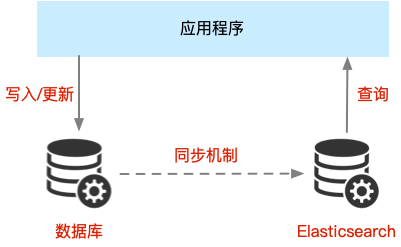
Elasticsearch与数据库的集成
指标分析/日志分析
- Data Collection(beats) -> Buffering(redis,Kafkak) -> Data Aggregation & Processing(logstash) -> Indexing & storage(elasticsearch) -> Analysis & visualization(Kbana)
Elasticsearch
Elasticsearch 目录结构
1
2
3
4
5
6
7
8
9
10
11
12
13ubuntu in ~/elasticsearch-7.14.1 at k8s-node1 took 45s
➜ tree -L 1
.
├── bin -- 脚本文件,包括启动elasticsearch,安装插件,运行统计数据
├── config -- elasticsearch.yml 集群配置文件,user, role based 相关配置
├── jdk -- Java 运行环境
├── lib -- Java 类库
├── LICENSE.txt
├── logs -- path.log 日志文件
├── modules -- 包含所有ES模块
├── NOTICE.txt
├── plugins -- 包含所有已安装插件
└── README.asciidocJVM 配置
1
2
3# 修改JVM - config/jvm.options
-Xms和Xms 最小最大内存设置成一样
-Xmx不超过机器内存的50Run
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20$ bin/elasticsearch
~ took 11m 31s
➜ curl http://localhost:9200
{
"name" : "a714f28827d5",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "96jmRuNUQxqFsGeWJjIo6g",
"version" : {
"number" : "7.14.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "66b55ebfa59c92c15db3f69a335d500018b3331e",
"build_date" : "2021-08-26T09:01:05.390870785Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Plugin 机制对系统扩展
Discovery Plugin
Analysis Plugin
Security Plugin
Management Plugin
Ingest Plugin
Mapper Plugin
Backup Plugin1
2
3
4
5
6
7
8
9
10
11
12
13
14
15ubuntu in ~ at k8s-node1 via 🐍 3.8.6
➜ elasticsearch-plugin install analysis-icu # 分词插件
-> Installing analysis-icu
-> Downloading analysis-icu from elastic
[=================================================] 100%
-> Installed analysis-icu
-> Please restart Elasticsearch to activate any plugins installed
ubuntu in ~ at k8s-node1 via 🐍 3.8.6 took 23s
➜ elasticsearch-plugin list
analysis-icu
ubuntu in ~ at k8s-node1 via 🐍 3.8.6
➜ curl http://localhost:9200/_cat/plugins
k8s-node1 analysis-icu 7.14.1-
1
2
3
4
5➜ curl -X GET "localhost:9200/_cat/nodes?v=true&pretty"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.24.0.2 41 97 85 4.28 1.24 0.43 cdfhilmrstw - es01
172.24.0.3 56 97 85 4.28 1.24 0.43 cdfhilmrstw - es03
172.24.0.4 27 97 85 4.28 1.24 0.43 cdfhilmrstw * es02 Kibana:
1
2
3
4
5
6$ curl http://localhost:5601
# Kibana Plugins 插件
$ kibana-plugin install
$ kibana-plugin list
$ kibana removeLogstash:
1
Elasticsearch 基本概念
文档 Document
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位
文档会被序列化成JSON格式,保存在Elasticsearch中
每个文档都有一个Unique ID1
2
3
4
5
6
7# 文档元数据Metadata - 标注文档的相关信息
_index - 文档所属的索引名
_type - 文档所属类型名
_id - 文档唯一ID
_source - 文档原始JSON数据
_version - 文档的版本信息 -- 解决并发读写冲突
_score - 相关性打分索引 Index
将文档写入Elasticsearch的过程叫索引indexing
1
2
3Mapping: 定义包含的文档的字段名和字段类型
Setting: 定义不同数据分布
Shard: 索引中的数据分散在Shards上节点 Node
节点是Elasticsearch 实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20-E node.name=node1
每个节点启动后,会分配一个UID,保存在data目录下
# Master-eligible nodes 和 Master Node
1. 节点启动默认是一个Master-eligible节点, -E node.master:false 禁止
2. Master-eligible节点可以参加选主流程,称为Master节点
3. 每个节点都保存集群状态,只有master节点才能修改集群状态
# 集群状态 Cluster State
1. 所有节点信息
2. 所有的索引和相关Mapping 与 Setting信息
3. 分片的路由信息
# Data Node & Coordinating Node
1. Data Node: 可以保存数据的节点,保存分片数据
2. Coordinating Node: 负责接受Client请求,将请求分发到合适的节点,最终把结果汇集到一起
# Hot & Warm Node
# Machine Learning Node
# Tribe Node分片 Primary Shard & Replica Shard
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#主分片: 解决数据水平扩展的问题
1. 一个分片是一个运行的Lucene的实例
2. 主分片在索引创建时指定,后续不允许修改,使用 Reindex修改
#副本: 解决数据高可用的问题
1. 副本分片数,可以动态调整
2. 增加副本数,可以在一定程度上提高服务的可用性 (读取的吞吐)
#分片设定-容量规划
1. 分片数设置过小:
a. 后续无法增加节点实现水平扩展
b. 单个分片的数据量过大,导致数据重新分配耗时
2. 分片设置过大:
a. 影响搜索结果的相关性打分,影响统计结果准确性
# 查看集群状态
Green: 主分片和副片正常
Yellow: 主分片正常,副片不正常
Red: 主分片未能分配Elasticsearch vs 关系型数据库 抽象与类比
| RDBMS | Elasticsearch |
|---|---|
| Table | Index |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
文档Document CRUD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37//create document. 自动生成_id
POST users/_doc
{
"user": "Mike",
"message": "trying out Kibana"
}
//create document. 指定Id, 如果ID已经存在,报错
PUT users/_doc/1?op_type=create
{
"user": "Jack",
"message": "trying out Elasticsearch"
}
//create document. 指定Id, 如果ID已经存在,报错
PUT users/_create/1
{
"user": "Jack",
"message": "trying out Elasticsearch"
}
// Get the document by ID
GET users/_doc/1
// Index
PUT users/_doc/1
{
"user": "Mike"
}
//Update 在原文档上增加字段
POST users/_update/1/
{
"doc":{
"message": "trying out Elasticsearch 3"
}
}- Bulk API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
181. 支持在一次API调用中,对不同的索引进行操作
2. 支持四种类型操作:
Index
Create
Update
Delete
3. 操作单条操作失败,不会影响其他操作
4. 返回结果包括每一条操作的执行结果
//Bulk操作
POST _bulk
{"index": {"_index": "test", "_id": "1"}}
{"field1": "value1"}
{"delete": {"_index": "test", "_id": "2"}}
{"create": {"_index": "test2", "_id": "3"}}
{"field1": "value3"}
{"update": {"_id":"1", "_index": "test"}}
{"doc": {"field2": "value2"}}
- Bulk API
mget
1
2
3
4
5
6
7
8
9//mget -- 批量读取
//可以减少网络连接,提高性能
GET _mget
{
"docs": [
{"_index": "users", "_id":1},
{"_index": "comment", "_id":1}
]
}
Elasticsearch 原理
- 图书和搜索引擎类比
| Type | 正排索引 | 倒排索引 |
|---|---|---|
| 图书 | 目录页 | 索引页 |
| 搜索引擎 | 文档ID->文档内容和单词的关联 | 单词到文档ID的关系 |
Elasticsearch 倒排索引
Elasticsearch的JSON文档中每个字段,都有自己的倒排索引
1
2
3
4
5
6
7
8
9
10
11# 单词词典(Term Dictionary)
> 记录所有文档的单词,记录单词到倒排列表的关联关系
> 通过B+树或哈希链表实现,满足高性能的插入与查询
# 倒排列表(Posting List)
> 记录单词对应的文档结合
- 倒排索引项(Posting)
- 文档ID
- 词频TF - 单词在文档出现的次数
- 位置Position - 单词在文档中分词的位置,用于语句搜索 phrase query
- 偏移Offset - 记录单词的开始结束位置,实现高量显示Elasticsearch 分词器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86# Analysis
- Analysis: 文本分析是把全文本转换一系列单词 term/token的过程
- Analysis是通过Analyzer实现
# Analyzer:
- Character Filters: 针对原始文本处理
- HTML strip - 去除html标签
- Mapping - 字符串替换
- Pattern repalce - 正则匹配替换
- Tokenizer: 将原始的文本按照一定的规则,切分为词 term or token
- whitespace
- standard
- uax_url_email
- pattern
- keyward
- path hierarchy
- Token Filter: 将切分的单词进行加工,小写,删除stopwords,增加同义词
- Lowercase
- stop
# Elasticsearch内置分词器
//默认分词器 standard
// 按词切分,小写处理
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over dogs in the summer evening."
}
//Simple Analyzer
// 按照非字母切分,非字母被去除
// 小写处理
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over dogs in the summer evening."
}
// Whitespace Analyzer
// 按照空格切分
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over dogs in the summer evening."
}
// Stop Analyzer
// stop filter: 去除the, a, is 修饰性词
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over dogs in the summer evening."
}
//Keyward Analyzer
//不分词,直接将输入当输出
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over dogs in the summer evening."
}
//正则表达式进行分词
//默认非字符的符号进行分隔
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over dogs in the summer evening."
}
//english
GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over dogs in the summer evening."
}
// analysis_icu
// elasticsearch-plugin install analysis_icu
POST _analyze
{
"analyzer": "icu_analyzer",
"text":"他说的确实在理"
}Search API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90# URI Search - 通过URI query实现搜索
q: 指定查询语句, 使用Query String Syntax
df: 默认字段, 不指定会对所有字段进行查询
Sort: 排序/from 和 size 用于分页
Profile: 查看查询是如何被执行
1. 指定字段 vs. 泛查询
//带profile 普通查询
GET /movies/_search?q=2012&df=title
{
"profile": "true"
}
//带profile 泛查询
GET /movies/_search?q=2012
{
"profile": "true"
}
//带profile 指定字段
GET /movies/_search?q=title:2012
{
"profile": "true"
}
2. Term vs. Phrase
# Term: Beautiful Mind 等效于 Beautiful OR Mind
# Phrase: "Beautifuk Mind" 等效于 Beautiful And Mind, 前后顺序保持一致
//使用引号 查询
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}
//使用引号 Mind 泛 查询
GET /movies/_search?q=title:Beautiful Mind
{
"profile":"true"
}
//使用引号 Bool 泛 查询
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile":"true"
}
3. 布尔操作
AND / OR / NOT 或者 && / || / !
title:(matrix NOT reloaded)
4. 分组
+ 表示 must
- 表示 must_not
title:(+matrix -reloaded)
5. 范围查询
[]闭区间 {}开区间
6. 算数符号
year:>2010
7. 通配符查询(通配符查询效率低,占用内存大,不建议使用)
? 代表1个字符
* 代表0或多个字符
8. 正则表达式
title:[bt]oy
9. 模糊匹配与近似查询
title:befutifl~1
# Request Body Search
1. 分页:
from, size
2. sort:
3. _source filtering: 如果_source没有存储,就只返回匹配的文档的元数据
4. 脚本字段:
5. 查询表达式 - Match
6. Match
# Page Rank算法
1. 衡量相关性 Information Retrieval
a. Precision (查准率) - 尽可能返回较少的无关文档
b. Recall(查全率) - 尽量返回较多的相关文档
c. Ranking - 是否能够按照相关度进行排序Mapping
类似数据库中的scehma定义
1
2
3
4
5
6
7
8
9
101. 定义索引中的字段名称
2. 定义字段的数据类型
Mapping 把JSON文档映射成Lucene所需要的扁平格式
一个Mapping属于一个索引的type
# 四种不同级别的Index Options - 控制倒排索引记录的内容
docs - 记录doc id
freqs - 记录 doc id 和 term frequencies
positions - 记录 doc id/term frequencies/term position
offsets - 记录 doc id/term frequencies/term position/character offsets数据类型
JSON -> Elasticsearch类型JSON类型 Elasticsearch 类型 字符串 匹配日期格式 -> Date 布尔值 boolean 浮点数 float 整数 long 对象 Object 数组 由第一个非空数值的类型所决定 空值 忽略
1 | # 简单类型: |
Elasticsearch 聚合 (Aggregation)
Elasticsearch 除了搜索以外还提供针对ES数据进行统计分析
- 集合分类
1
2
3
4
5
6
7
81. Bucket Aggregation: 满足特定条件的文档集合
group by
2. Metric Aggregation: 数学运算,对文档字段统计分析
min/max/sum/avg/cardinality
3. Pipeline Aggregation: 对聚合结果进行二次聚合
4. Matrix Aggregation: 支持多个字段的操作并提供结果矩阵
Elasticsearch 分布式结构
高可用
1
21. 服务可用性 - 允许有节点停止服务
2. 数据可用性 - 部分节点丢失,不会丢失数据可扩展性
1
1. 请求量提升/数据不断增加(将数据分布到所有节点上)
Elasticsearch分布式架构
1
1. 不同的集群通过不同的名字区分,-E cluster.name=geektime