Redis Tips & Tracks
Redis
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker.
Redis知识的全景图
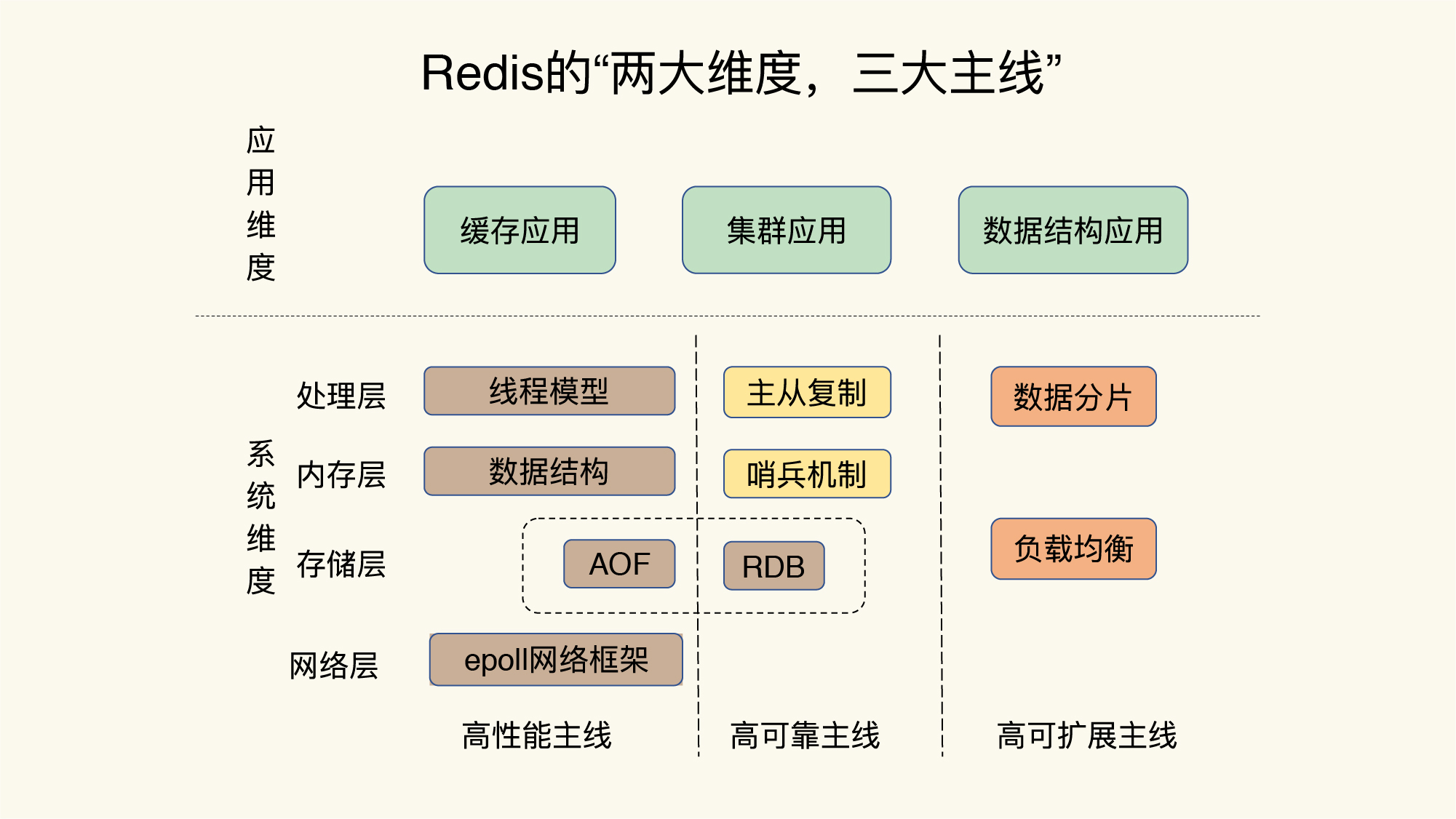
- 应用纬度:
- 缓存应用
- 内嵌Key过期机制和淘汰策略
- 集群应用
- 主从集群、切片集群
- 数据结构应用
- String
- Hash
- List
- Set
- Sorted Set
- 缓存应用
- 系统纬度:
- 处理层:
- 线程模型
- 内存层:
- 数据结构
- 存储层:
- AOF
- RDB
- 网络层:
- epool网络框架
- 处理层:
- 高性能主线:
- 线程模型
- 数据结构
- 集合类型采用有序索引,可以支持范围操作
- 考虑不同数据结构的内存效率、设计了压缩列表、整数数组这些精简的底层数据结构、节省内存开销
- 内存分配器
- jemalloc和tcmalloc比glibc效率高
- 持久化
- 支持RDB、AOF持久化数据,支持主从库集群
- 网络框架
- 高可用主线:
- 主从复制
- 哨兵机制
- 切片集群
- 高扩展主线:
- 数据分片
- 负载均衡
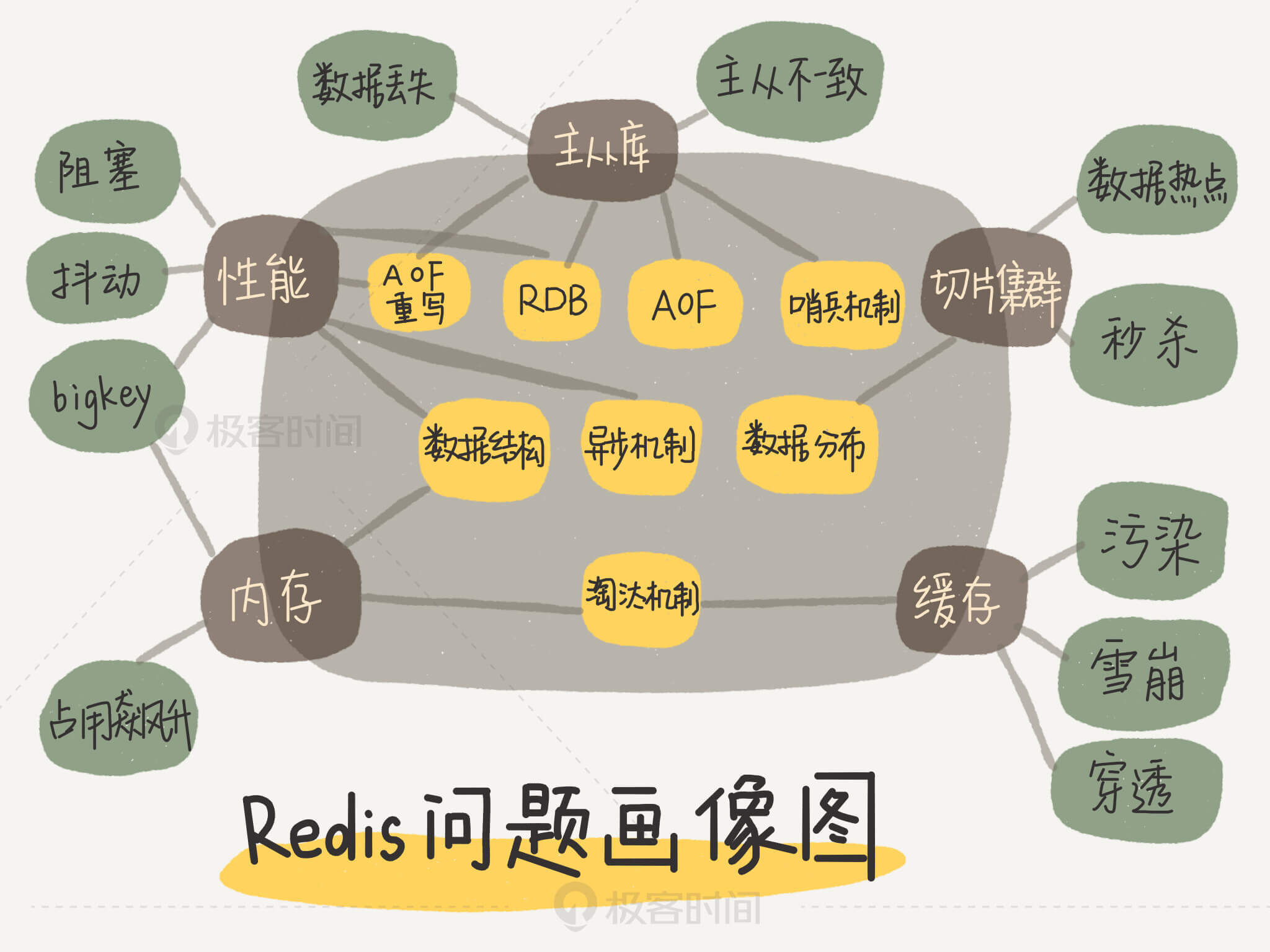
Redis问题画像图
Redis 基础
基础架构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84# 数据模型: key-value
> Redis能够在实际业务场景中广泛的应用,就是得益于支持多样化类型的value
# 操作接口:
- PUT:
- GET:
- DELETE:
- SCAN:
# 访问框架:
- 动态库访问
- 网络框架访问:包括Socket Server和协议解析
# 操作模块:
- Redis 键-值映射数据类型
- 哈希表: 就是一个数组,数组的每个元素netry称为一个哈希桶(桶中元素存储的是指向key和value的指针).
- O(1)时间复杂度快速查找键值对
- 哈希表冲突问题
- Redis解决哈希冲突使用链式哈希,指向同一个哈希桶中的多个元素用链表保存,之间依次用指针连接
- Rehash操作:
- 装载因子 load factor = 所有entry个数/哈希表的哈希桶个数
- rehash操作就是增加现有哈希桶数量,让增多的entry元素能在更多的桶之间分散保存,减少单个桶中元素数量,从而减少单个桶中冲突
- Redis默认采用两个全局哈希表,哈希表1,哈希表2, Rehash过程:
- hash2分配更大空间 2 * hash1
- 将hash1中数据重新映射并拷贝到hash2
- 释放hash1空间
- 渐进式rehash:
- 巧妙的把一次性大量拷贝的开销分摊到多次处理请求的过程中,避免耗时操作,保证数据的快速访问
- Redis值的数据类型:
- 字符串String:
- 底层数据类型:
- 简单动态字符串
- 列表List
- 底层数据类型:
- 双向链表
- 压缩列表
- 集合Set
- 底层数据类型
- 压缩列表
- 整数数组
- 有序集合Sorted Set
- 底层数据类型
- 压缩列表
- 跳表
- 哈希Hash
- 底层数据类型
- 压缩列表
- 哈希表
- Redis底层数据结构
> Redis之所以采用不同的数据结构,是在性能和内存使用效率之间进行平衡
- 简单动态字符串
- 双向链表
- 压缩列表:类似数组
- 表头:
- zlbytes: 列表长度
- zltail: 列表尾的偏移量
- zllen: 列表中entry个数
- 表尾:
- zlend: 表示结束
- 哈希表
- 跳表: 跳表在链表的基础上增加多级索引,通过索引位置的几个跳转,实现数据的快速定位
- 查找复杂度O(logN)
- 整数数组
# 索引模块:
- 索引的作用是让键值数据库根据Key找到响应value的存储位置,进而执行操作
- 哈希表: redis, mamcached采用
- 内存的高性能随机访问可以很好与哈希表O(1)操作复杂度相匹配
- B+树
- 字典树
- skip list: RocksDB采用
# 存储模块:
- 内存分配器
- glibc: malloc/free
- 持久化
- 日志AOF
- 快照RDB
# IO模型设计
> Redis单线程是指网络IO和键值对读写是由一个线程完成. 其他功能持久化、异步删除、集群数据同步是由额外的线程执行.
- 多线程编程模式:
- 面临共享资源的并发访问控制问题
- 采用多线程开发会引入同步原语来保护共享资源的并发访问
- 单线程编程模式:
- Redis基本IO模型中,主要是主线程在执行操作,任何耗时的操作,bigkey、全量返回等操作,都是潜在的性能瓶颈Socker网络模型
调用方法 返回套接字类型 非阻塞模式 效果 socket() 主动套接字 listen() 监听套接字 可设置 accept()非阻塞 accept() 已连接套接字 可设置 send()/recv()非阻塞 Redis多路复用IO模型
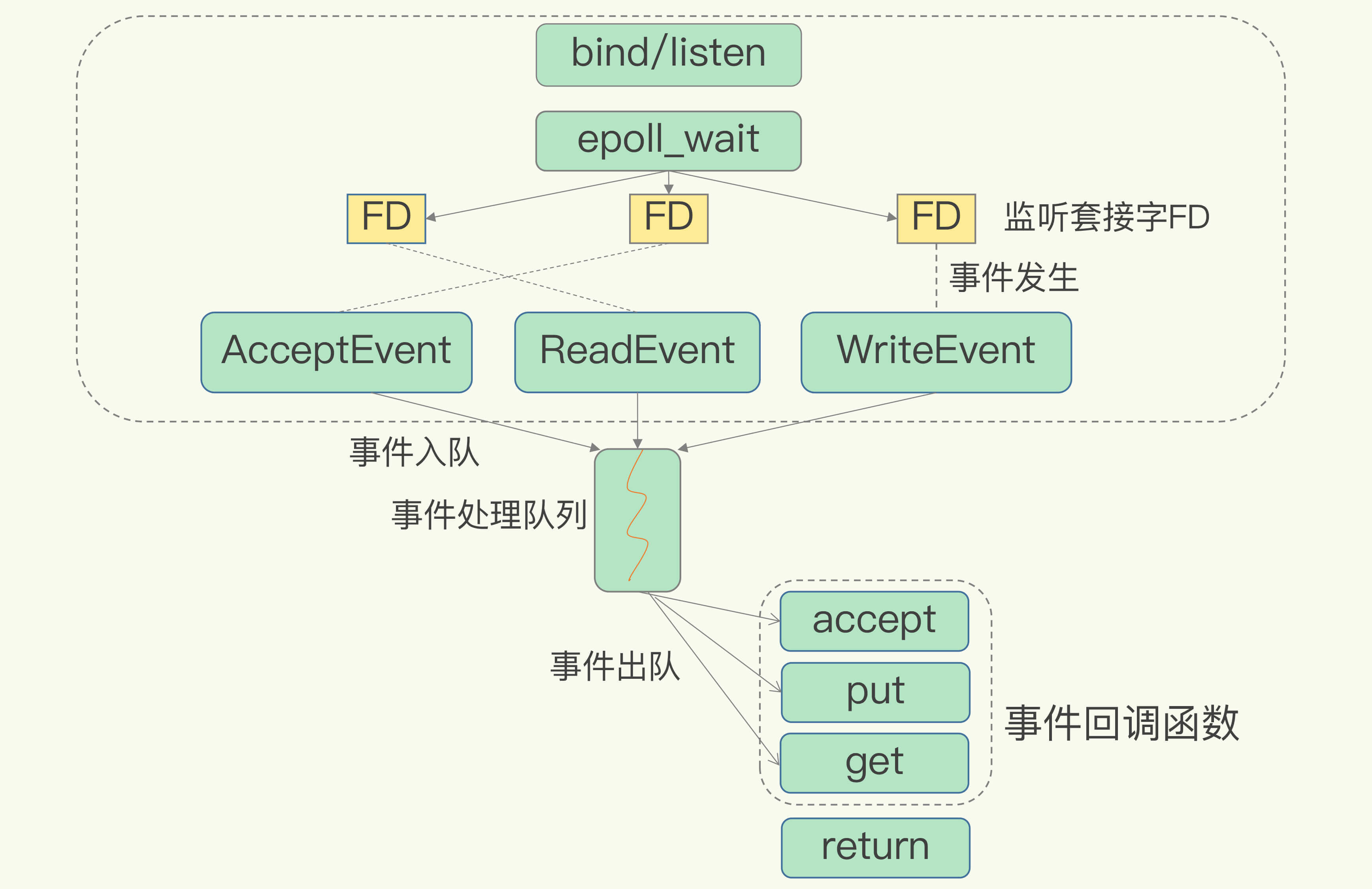
一个线程处理多个IO流.该机制允许内核中同时存在多个监听套接字和已连接套接字.
select/epoll提供基于事件的回调机制,针对不同事件的发生,调用响应的处理函数底层数据结构时间复杂度分类
名称 时间复杂度 哈希表 O(1) 跳表 O(logN) 双向链表 O(N) 压缩列表 O(N) 整数数组 O(N) 1
2
3
4
5
6
- 范围操作是指集合类型中的遍历操作: O(N)
- SCAN操作实现渐进式遍历,只返回有限数量的数据.
压缩列表和双向链表都会记录表头和表尾的偏移量
源码分析
- 通信协议
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24redis客户端和服务器发送的命令和数据一律以\r\n (CR LF)结尾
# 请求协议:
*<参数数量> CR LF
$<参数的字节数量> CR LF
<参数的数据> CR LF
ubuntu in / at 3BPlus took 11s
➜ tail appendonly.aof
*3 - 表示当前命令有单个部分
$3 - 字节数
set
$4
name
$10
chyiyaqing
# 回复协议:
> 在回复协议中,可以通过检查第一个字节,确定这个回复是什么类型
- 状态回复 (status reply) 第一个字节是 "+"
- 错误回复 (error reply) 第一个字节是 "-"
- 整数回复 (integer reply) 第一个字节是 "."
- 批量回复 (bulk reply) 第一个字节是 "$"
- 多条批量回复 (multi bulk reply) 第一个字节是 "*"
性能调优
数据持久化
Redis 持久化主要两大机制: AOF (Append Only File) 日志和RDB 快照
AOF - Append Only File
1
AOF日志是Redis执行完命令,把数据写入内存,然后才记录日志,避免出现记录错误命令的情况,记录的是Redis收到的每一条命令, 这些命令以文本形式保存
- AOF 潜在的风险
1
2
3
4
5
6
7
8
9- 执行完命令还没有来得及记日志就宕机,这个命令和相关的数据有丢失的风险?
- AOF写日志在主线程中执行,如果磁盘写压力过大,就会导致写盘很慢,进而导致后续的操作无法执行
# 写回磁盘策略 appendfsync
1. Always: 同步写回, 每个写命令执行完,立马同步将日志写回磁盘
> 落盘操作属于慢速,回影响主线程性能
2. Everysec: 每秒写回,每个写命令执行完,先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘
> 在避免影响主线程和避免数据丢失两者之间trade-off方式
3. No: 操作系统控制写回,每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
> 落盘时机交给操作系统,只要AOF记录没有写回磁盘,宕机对应的数据就丢失配置项 写回时机 优点 缺点 Always 同步写回 可靠性高,数据基本不丢失 每个写命令都要落盘,性能影响较大 EverySec 每秒写回 性能适中 宕机时丢失1秒内的数据 No 操作系统控制写回 性能好 宕机丢失数据较多 - AOF文件过大的性能问题
1
2
31. 文件系统本身对文件大小有限制,无法保存过大的文件
2. 文件过大,追加命令记录效率变低
3. 发生宕机,AOF记录命令要被重新执行,故障恢复比较缓慢,会影响Redis正常使用 - AOF重写机制:
1
2
3
4
5
6直接根据数据库中数据的最新状态,生成这些数据的插入命令
> 重写机制可以将旧日志文件中的多条命令,在重写后的新日志中变成一条命令
> AOF重写过程是由后台子进程bgrewriteaof完成,避免阻塞主线程,导致性能下降
- "一个拷贝,两处日志"
- 一个拷贝: 每次执行重写时,主线程fork出后台的bgrewriteaof子进程,此时,fork会把主线程的内存拷贝一份给bgrewriteaof子进程,然后bgrewriteaof子进程在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志.
- 两处日志: 一个是正在使用的AOF日志,Redis会把操作写到它的缓冲区,第二处日志是新的AOF重写日志,等到拷贝数据的所有操作记录重写完成后,重写日志记录的操作也会写入新的AOF文件,保证数据库最新状态的记录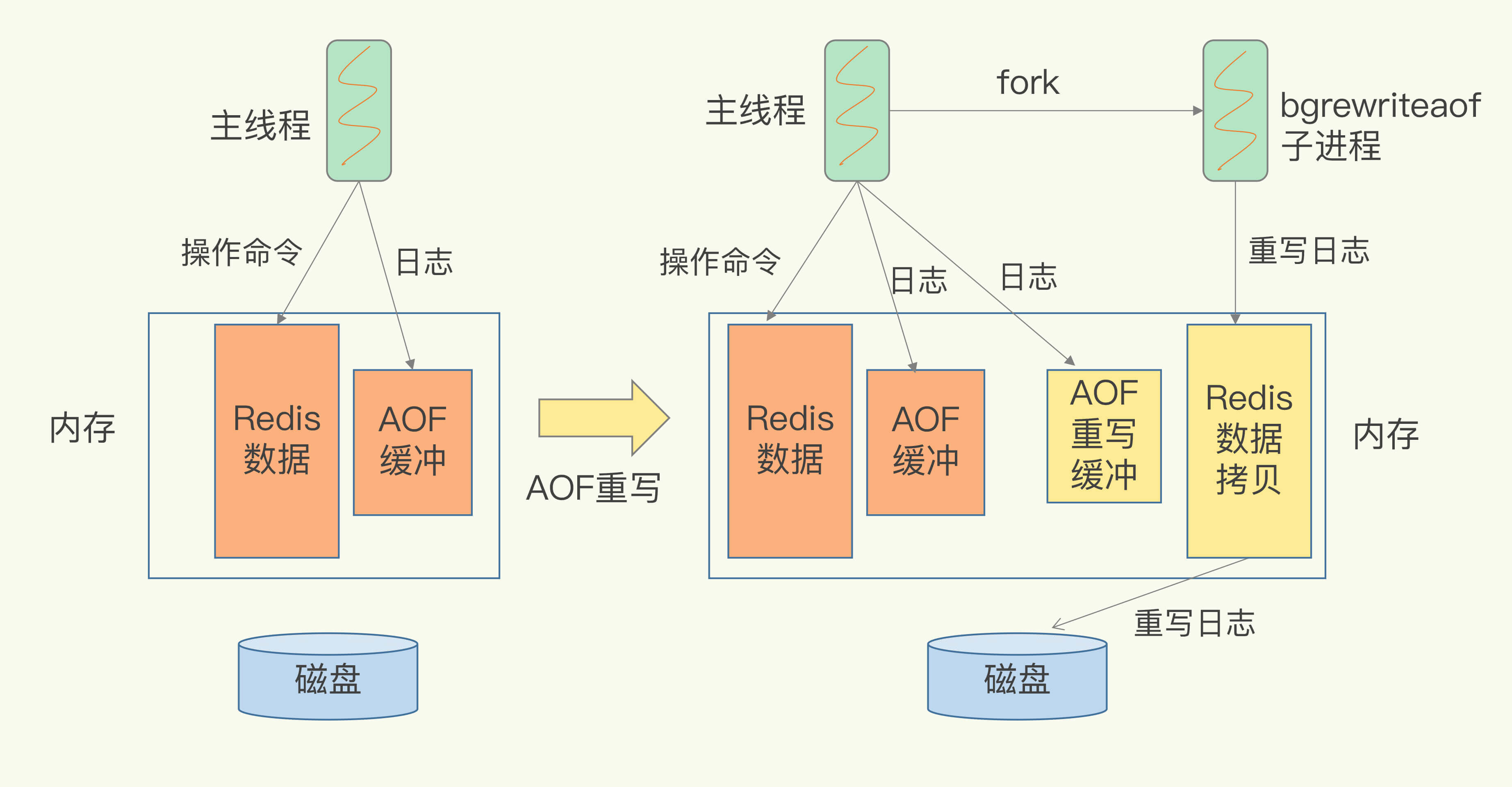
- AOF 潜在的风险
RDB(Redis DataBase) - 内存快照
1
内存快照:指内存中的数据在某一个时刻的状态记录
- Redis两种命令生成RDB文件
- save: 在主线程执行,会导致阻塞
- bgsave: 创建子进程,专门用于写入RDB文件,避免主线程阻塞, 默认配置
1
2
3> bgsave子进程由主线程fork生成,共享主线程的所有内存数据,bgsave子进程运行后,开始读取主线程的内存数据,并把数据写入RDB文件
1. 频繁将全量数据写入磁盘,会给磁盘带来很大压力.
2. bgsave子进程需要fork操作从主线程创建出来, fork操作会阻塞主线程
- COW - Copy-On-Write
1
2写时复制技术具体来说,主线程在有写操作时,才会把这个新写或者修改的数据写入到新的物理地址,并修改自己的页表映射.
保证快照的完整性,也允许主线程同时对数据进行修改,避免对正常业务的影响 - Redis 4.0 混合AOF+RDB
1
2
3
4
5# 增量快照:
> 做一次全量快照后,后续的快照支队修改的数据进行快照记录,可以避免每次全量快照的开销
# 混合使用AOF日志和内存快照
> 内存快照以一定的频率执行,两次快照之间,使用AOF日志记录这期间的所有命令操作
- Redis两种命令生成RDB文件
数据同步
- Redis 主从库模式
1
2
3> 主从库采用读写分离方式
- 读操作: 主库、从库都可以接收
- 写操作: 首先到主库执行,然后,主库将写操作同步给从库- 主从库如何进行第一次同步?

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 三个阶段
1. 第一阶段: 建立连接、协商同步
- psync ? -1
- runID: Redis实例自动生成的随机ID
- offset: 复制的偏移量
- FULLRESYNC: 表示第一次复制采用全量复制,主库会把当前所有的数据都复制给从库
2. 第二阶段: 主库同步数据给从库
- 主库将所有数据同步给从库,从库收到数据后,在本地完成数据加载
- replication buffer: 主从库在进行全量复制时,主库上用于和从库连接的客户端buffer
3. 第三阶段: 主库发送新写命令给从库
- 主库把replication buffer 操作发给从库
- 主库会给每个从库建立一个客户端,所以replication buffer不是共享的,而是每个从库都有一个对应的客户端
# 主从库复制采用RDB,不采用AOF?
1. RDB 文件是二进制文件,无论要把RDB写入磁盘还是通过网络传输RDB,IO效率比记录的纯文本AOF高
2. 在从库进行恢复时,用RDB的恢复效率比AOF高 - 主 - 从 - 从
1
通过“主-从-从”模式将主库生成RDB和传输RDB的压力,以级联的方式分散到从库中
- 基于长连接的命令传播
1
2
- 主从库如何进行第一次同步?
- 哨兵机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
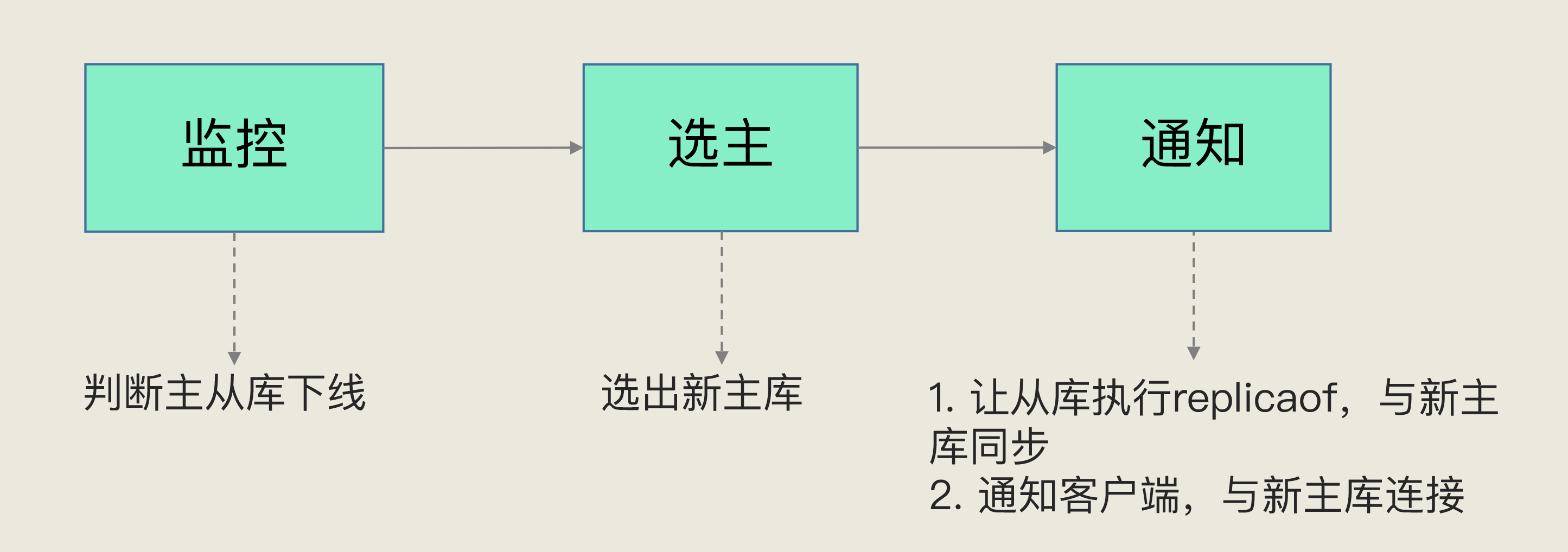
27> Redis主从集群中,哨兵机制实现主从库自动切换, 解决主从复制模式下故障转移
# 哨兵集群:
> 采用多实例组成的集群模式进行部署, 引入多哨兵判断避免单个哨兵自身网络状态不好,误判主库下线
> N个哨兵实例,最好要有N/2+1实例判断主库为"主观下线", 最终判定主库为“客观下线”
# 哨兵负责的任务:
- 监控
- 周期性向所有的主从库发送PING命令
- 哨兵对主库下线判断:
- 主观下线: 哨兵进程使用PING命令检测自己和主、从库的网络连接情况,判断实例的状态
- 误判: 发生在集群网络压力较大、网络拥赛,或者主库本身压力较大
- 客观下线:
- 选主
- 主库挂了之后,哨兵需要从很多从库中选择一个从库实例
- "筛选" + "打分":
- "筛选": 检查从库的当前在线状态,判断网络连接状态
- "打分": 从库优先级、从库复制进度以及从库ID号
- replica-priority 100
- 通知
- 哨兵会把新主库的连接信息发给其他从库,让他们执行replicaof命令,和新主库建立连接,并进行数据复制,同时哨兵把新主库的连接信息通知给客户端,请求操作发到新主库上.
# 基于pub/sub 机制的哨兵集群
> 哨兵只要和主库建立连接,就可以在主库上发布消息,比如发布自己的连接信息(IP和端口),从主库上订阅消息,获取其他哨兵发布的连接信息
- 哨兵获取从库的IP+端口
- 哨兵向主库发送INFO命令,查看从库列表,进而与从库建立连接
- pub/sub客户端事件通知
Redis切片集群
1 | 切片集群(分片集群)可以保存大量数据,对Redis主线程阻塞影响较小 |
- 纵向扩展(scale up):
- 横向扩展(scale out):
- Redis Cluster:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16> Redis Cluster 采用哈希槽(Hash Slot)处理数据和实例之间的映射关系. 2^14
1. 根据键值key,按照CRC16算法计算16-bit值,然后对16384取模,每个摸数代表响应编号的哈希槽。
> 客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令
127.0.0.1:6001> get name
-> Redirected to slot [5798] located at 172.30.1.23:6002
"chyiyaqing"
172.30.1.23:6002>
ASK命令并不会更新客户端缓存的哈希槽分配信息
更改本地缓存,让后续所有命令都发往新实例
- Redis Cluster:
Redis 应用场景 - 消息队列
1 | # 消息队列需要满足的功能: |
List - 队列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40ubuntu in ~ at 3BPlus
➜ redis-cli -c -p 6001
127.0.0.1:6001> ping
PONG
127.0.0.1:6001> LPUSH queue msg1 # 增加消息
-> Redirected to slot [13011] located at 172.30.1.23:6003
(integer) 1
172.30.1.23:6003> LPUSH queue msg2
(integer) 2
172.30.1.23:6003> RPOP queue # 拉取消息
"msg1"
172.30.1.23:6003> RPOP queue
"msg2"
127.0.0.1:6001> RPOP queue # 队列为空,RPOP返回NULL
-> Redirected to slot [13011] located at 172.30.1.23:6003
(nil)
127.0.0.1:6001> BRPOP queue 5 # BRPOP阻塞式拉取消息,支持传入超时时间
-> Redirected to slot [13011] located at 172.30.1.23:6003
(nil)
(5.00s)
172.30.1.23:6003> BRPOP queue 0 # 不设置超时,直到有新消息才返回
^C
172.30.1.23:6003> exit
注意: 如果设置超时时间太长,连接太久没有活跃,有可能会被Redis server判定为无效连接,之后Redis Server会强制把这个客户端踢下线,客户端要有重连机制
1. 不支持重复消费:消费者拉取消息后,该消息就从List中删除,无法被其他消费者在此消费,即不支持多个消费者消费同一批数据
2. 消息丢失,消费者拉取到消息后,如果发生异常宕机,这条消息就丢失
# 单机测评
ubuntu in ~ at 3BPlus took 37s
➜ redis-benchmark -n 1000000 -t lpush,rpop -P 16 -q -h 127.0.0.1 -p 6001 --cluster
Cluster has 3 master nodes:
Master 0: a733c21d3b735b9d026eb4d462ef6b367d8ebb98 172.30.1.23:6002
Master 1: 9c35a4e211f6534861ed768dba592e85539b1377 172.30.1.23:6003
Master 2: a901e497cb72819cf0765e9e4eb16c36399c437b 172.30.1.23:6001
LPUSH: 41529.96 requests per second, p50=17.199 msec
RPOP: 46539.77 requests per second, p50=15.463 msecPub/Sub - 发布订阅模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62# 消费者1
ubuntu in ~ at 3BPlus
➜ redis-cli -c -p 6001
127.0.0.1:6001> SUBSCRIBE queue
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "queue"
3) (integer) 1
1) "message"
2) "queue"
3) "msg1"
# 消费者2
ubuntu in ~ at 3BPlus
➜ redis-cli -c -p 6001
127.0.0.1:6001> SUBSCRIBE queue
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "queue"
3) (integer) 1
1) "message"
2) "queue"
3) "msg1"
# 生产者
ubuntu in ~ at 3BPlus
➜ redis-cli -c -p 6001
127.0.0.1:6001> PUBLISH queue msg1
(integer) 2
127.0.0.1:6001> PUBLISH queue msg2
(integer) 2
127.0.0.1:6001> exit
# Pub/Sub 支持阻塞式拉取消息,满足多组消费者,匹配订阅模式,允许消费者订阅多个队列
127.0.0.1:6001> PUBLISH queue.p1 msg1 -- 生产者
(integer) 1
127.0.0.1:6001> PUBLISH queue.p2 msg2
(integer) 1
127.0.0.1:6001> PSUBSCRIBE queue.* -- 消费者 匹配订阅
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "queue.*"
3) (integer) 1
1) "pmessage"
2) "queue.*"
3) "queue.p1"
4) "msg1"
1) "pmessage"
2) "queue.*"
3) "queue.p2"
4) "msg2"
# Pub/Sub 实现原理
> 没有基于任何数据类型,没有做任何数据存储,只是单纯地为生产者、消费者建立数据转发通道,把符合规则的数据,从一端转发到另一端
> **在使用Pub/Sub时,消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失**
> List属于“拉取模式”, Pub/Sub属于“推模式”
# 注意使用Pub/Sub会丢数据
1. 消费者下线,重新上线,只能接收新的消息,在下线期间生产者发布的消息,因为找不到消费者,会被丢弃掉.
2. Redis宕机, Pub/Sub相关操作,不会写入RDB和AOF中,当Redis宕机重启,Pub/Sub的数据会全部丢失
3. 消费堆积, 每个消费者订阅一个队列,Redis都会在Server给消费者分配一个【缓冲区】,这个缓冲区其实就是一块内存,当生产者发布消息时,Redis先把消息写到对应消费者的缓冲区,之后消费者不断从缓冲区读取、处理消息, 缓冲区上线,会被强制下线.Stream
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61# Stream 通过XADD 和 XREAD完成简单的生产、消费模型
XADD: 发布消息
XREAD: 读取消息
# 生产者发布消息
127.0.0.1:6001> XADD queue * name 2021 # * 表示自动生成唯一消息ID
-> Redirected to slot [13011] located at 172.30.1.23:6003
"1630886765690-0" #消息ID格式: 时间戳-自增序号
172.30.1.23:6003> XADD queue * name 09-06
"1630886777470-0"
172.30.1.23:6003>
# 消费者消费消息
127.0.0.1:6001> XREAD COUNT 5 STREAMS queue 0-0 # 从开头读取5条消息,0-0表示从开头读取
-> Redirected to slot [13011] located at 172.30.1.23:6003
1) 1) "queue"
2) 1) 1) "1630886765690-0"
2) 1) "name"
2) "2021"
2) 1) "1630886777470-0"
2) 1) "name"
2) "09-06"
172.30.1.23:6003> XREAD COUNT 5 STREAMS queue 1630886777470-0 # 继续拉取消息,传入上一条消息的ID
172.30.1.23:6003> XREAD COUNT 5 BLOCK 0 STREAMS queue 1630886777470-0 # BLOCK 阻塞式拉取消息
# Stream 支持发布/订阅模式
- XGROUP: 创建消费者组
- XREADGROUP: 在指定消费组下,开启消费者拉取消息
172.30.1.23:6003> XGROUP CREATE queue group1 0-0 # 创建消费者组1, 0-0表示从头拉取消费
OK
172.30.1.23:6003> XGROUP CREATE queue group2 0-0 # 创建消费者组2,0-0
OK
172.30.1.23:6003> XREADGROUP GROUP group1 consumer COUNT 5 STREAMS queue > # group1 的consumer开始消费,>表示拉取最新数据
1) 1) "queue"
2) 1) 1) "1630886765690-0"
2) 1) "name"
2) "2021"
2) 1) "1630886777470-0"
2) 1) "name"
2) "09-06"
3) 1) "1630887243865-0"
2) 1) "name"
2) "08-14"
172.30.1.23:6003> XREADGROUP GROUP group2 consumer COUNT 5 STREAMS queue >
1) 1) "queue"
2) 1) 1) "1630886765690-0"
2) 1) "name"
2) "2021"
2) 1) "1630886777470-0"
2) 1) "name"
2) "09-06"
3) 1) "1630887243865-0"
2) 1) "name"
2) "08-14"
172.30.1.23:6003> XACK queue group1 1630887243865-0 # XACK 命令告知Redis消费者处理完
(integer) 1
# Stream 数据会写入RDB和AOF做持久化A
# 消息堆积,Stream会只保留固定长度的新消息,当队列长度超过上限,就消息会被删除,只保留固定长度的新消息
Redis面试
- 击穿、穿透、雪崩?
- 击穿
1
2
3
4
5
6
7
8
9
10
11
- Key过期
> Key有过期时间,如果某一个时刻Key失效,那么之后的查询请求将全部压倒数据库上,导致数据库崩溃.
- Key被页面置换淘汰
> 内存有限,要时刻缓存新的数据,淘汰旧的数据
> 由于Key过期在所难免,大流量来到Redis时,根据Redis的单线程特性,可以认为任务是在队列里一次执行,当请求到达redis发现key过期,进行一个操作: 设置锁
1.请求到达Redis,发现Redis Key过期,查看有没有锁,没有锁的话回到队列后面排队
2.设置锁,注意,这儿应该是setnx(),而不是set(),因为可能有其他县城已经设置锁了
3.获取锁,拿到就去数据库取数据,请求返回后释放锁
- 击穿
穿透
1
穿透主要原因是很多请求都在访问数据库不存在的数据,应对这种请求的处理办法对访问请求加一层过滤器(布隆过滤器、增强版布隆过滤器、布谷鸟过滤器)
雪崩
1
2
3
4
5> 雪崩和击穿类似,不同的是击穿是一个热点Key某时刻失效,而雪崩是大量的热点Key在一瞬间失效
1. 查看Key过期是不是时点性有关,时点性无关的话,可以随机过期时间解决
2. 如果是时点性有关,利用强依赖击穿方案,单飞策略(先过去的线程更新一下所有Key,在后台更新热点Key的同时,业务层将进来的请求延时一下)