MySQL Tips & Tracks
数据库-三大范式
- 原子性: 字段不可分
- 唯一性: 有主键(没有主键就没有唯一性),非主键字段依赖主键
- 消除冗余: 每列都与主键有直接关系, 非主键字段不能相互依赖
MySQL事务模型 ACID
MySQL事务的四个特性中ACD三个特性是通过Redo Log(重做日志)和Undo Log(撤销日志)实现,而I隔离型通过Lock实现
事务是可以提交或回滚的原子工作单元
ACID模型是一组数据库设计原则
1
2
3
4A: atomicity原子性: 事务中一系列的操作,要么全部都执行,要么全部都不执行
C: consistency一致性(通过AID保证): 数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性
I: isolation 隔离性(事务的隔离级别): 并发环境下,不同事务同时操作相同的数据,每个事务都有各自的完成数据空间
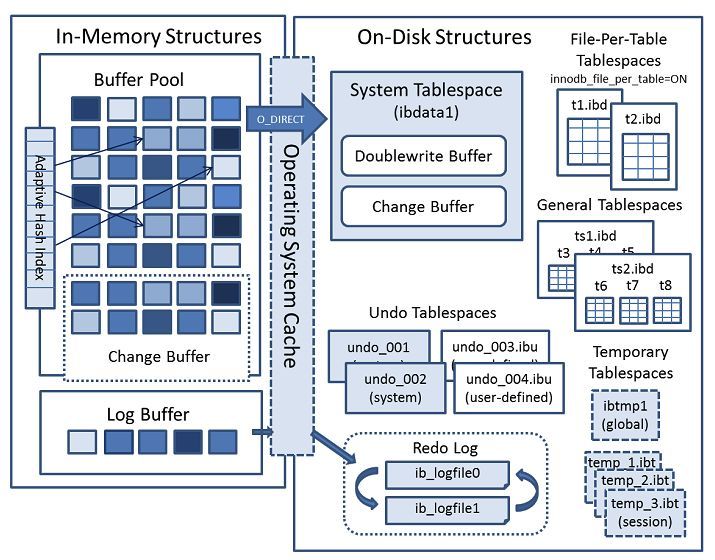
D: durability持久性: 只要事务成功结束,对数据库所做的更新就永久保存下来,即使发生系统崩溃,重新启动数据库,数据库还能恢复到事务成功结束时的状态InnoDB 存储引擎架构
并发问题
- 脏读: Drity Read: 读取到未提交的数据
- 不可重复读: Non-repeatable read: 两次读取结果不同
- 幻读 Phantom Read: select操作得到的结果所表证的数据状态无法支撑后续的业务操作
InnoDB 四种隔离级别
- READ UNCOMMITED 读未提交 –> 脏读
- READ COMMITTED 读已提交 –> 不可重复读
- REPEATABLE READ 可重复读 –> 幻读
- SERIALIZABLE 串行化
数据库日志
WAL - Write Ahead Log
实际写数据前,先把修改的数据记到日志文件中,以便故障时进行修复
重做日志 - redo log
1
2
3
4
5
6
7
8
9
10
11
12记录修改后的数据
用于异常恢复
循环写文件
> write Pos: 写入位置
> Check Point: 刷盘位置
> Check Point -> Write Pos: 待落盘
> innodb_flush_log_at_trx_commit: 刷盘时机
>> 0 commit 每秒写文件,并刷盘
>> 1 commit 每次提交时写文件,
MySQL redo-log:
1. 体积小,记录页的修改,比写入页代价低
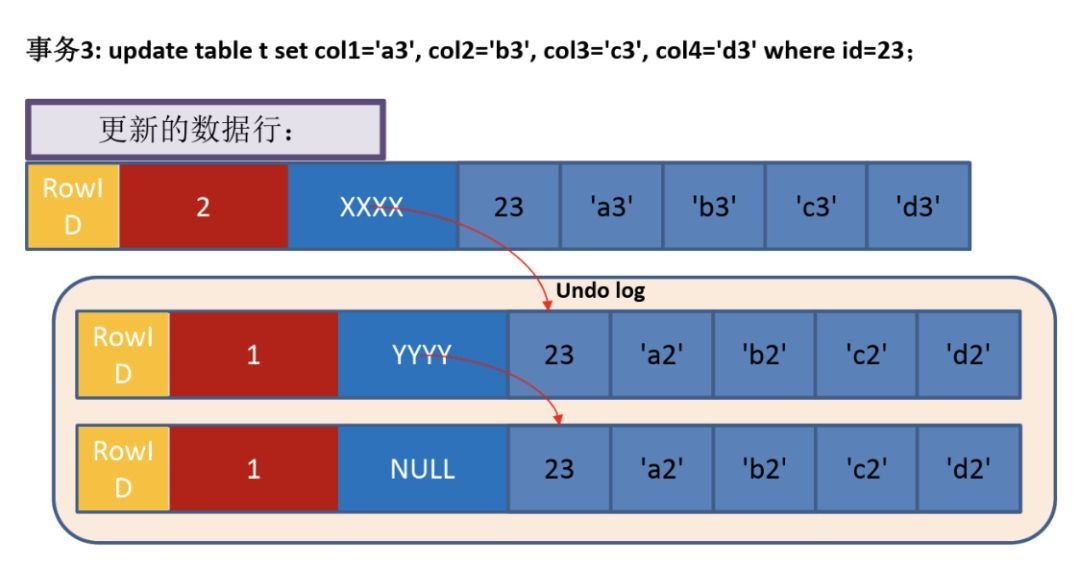
2. 末尾追加,随机写变顺序写,发生改变的页不固定回滚日志 - Undo Log
回滚日志记录的集合,包含如何撤销事务对聚集索引记录的最新更新的信息
MySQl多版本并发控制 - MVCC
使得InnoDB的事务隔离级别下执行一致性读操作有保证, 查询一个被另一个事务更新的行,可以看到被更新之前的值
多版本并发控制,解决读写冲突问题
- InnoDB MVCC实现
- 当前读 – Select for update
- 快照读 – Select Current_TRX_ID
- 可见性判断
- 创建快照这一刻,还未提交的事务,在此生命周期中无法读取
- 创建快照之后创建的事务无法读取
- Read View
- 快照读 活跃事务列表
- 活跃事务列表中最小事务ID
- 活跃事务列表中最大事务ID
1
2
3
4InnoDB向数据库中存储的每一行数据添加三个字段隐藏字段
1. DB_TRX_ID: 6字节 表示插入或更新最后一个事务的事务标识符 全局递增
2. DB_ROLL_PTR: 7字节 回滚指针 roll pointer, 指向写入回滚段撤销日志Undo Log
3. DB_ROW_ID: 6字节 随着新行插入而单调增加的行ID
- InnoDB Locking
- Shared and Exclusive Locks - 共享锁和排他锁
- A Shared Lock 允许持有锁的事务读取该行
- An Exclusive Lock 允许持有锁的事务更新和删除该行
1
2
3
4
5假设事务T1对数据行r持有共享锁(Shared Lock),另一个事务T2对同一数据行r的操作分下面两种情况:
1. T2对数据行r仅仅是读取请求持有(Shared Lock)成功,结果是T1和T2对数据行r都持有共享锁
2. T2对数据行人需要Update请求持有(Exclusive Lock)会失败
假设事务T1对数据行r持有排他锁(exclusive lock),另一个事务T2对同一数据行r的锁请求(共享锁/排他锁)都会失败,事务T2不得不等待事务T1释放锁
- Shared and Exclusive Locks - 共享锁和排他锁
MySQL 存储引擎
Page
1
2
3
4
5
6
7
8
9
10
11
12> 页Page : 16KB, 存储IO的基本单元
Page Header: 页头, 记录页面的控制信息,占用56字节,包括页的左右兄弟页面指针,页面空间使用情况
虚记录:
最大虚记录,比页内最大主键大
最小虚记录,比页内最小主键小
记录堆: 行记录存储区
有效记录
已删除记录
自由空间链表: 已删除记录组成的链表
未分配空间: 页内未使用的存储空间
Slot 区: 连续空间平均分配
Page Tailer: 页尾, 占8字节,存储页面的校验信息索引B+树
1
2
3
4
5
6
7
8
9
10
11# 顺序保证
- 物理有序: 数组,二分查找, 支持随机读,
- 逻辑有序: 链表, 支持随机写,
# 插入策略
- 自由空间链表
- 未使用空间
- 收缩数据库,解决数据库page碎片
# 页内查询
- 遍历
- 二分查找
- skip listInnoDB内存管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28- 预分配内存空间:
- Buffer Pool(预分配内存池):页面加载单位Page
- Page: Buffer Pool 的最小单位
- Free List: 空闲Page组成的链表
- Flush List: 脏页列表
- Page Hash表: 维护内存Page和文件Page的映射关系
- LRU: 内存淘汰算法- 释放刷盘
LRU_new: 存储热数据
LRU_old: 存储冷数据
Midpoint:
- 数据页面加载单元:
- 磁盘数据到内存
- 数据内外存交换:
- 内存管理的技术点:
- 内存池
- 内存页面管理
- 空闲页
- 数据页
- 脏页: 数据被Update 需要刷盘
- 页面映射
- 页面数据管理
- 数据淘汰:
- LRU: 最经常被访问的数据放在表头,默认删除表尾
- LFU: 使用频率淘汰算法, Redis 使用使用LFU淘汰算法
- 双LRU: 热表LRU,冷表LRU
- 全表扫描对内存的影响?
> 导致热数据被替换, 缓冲区被污染,导致数据库性能下降
- 避免全表扫描对热数据的影响
MySQL 锁实现原理
锁颗粒度
- 行级锁
- 作用在索引(聚簇索引、二级索引)行
- 是否是唯一索引
- 间隙锁
- 解决可重复读模式下的幻读问题
- GAP锁不是加载记录上
- GAP锁锁住的位置是两条记录之间的GAP
- 保证两次当前读返回一致的记录
- 表级锁
- lock tables
- 元数据锁(meta data lock, MDL)
- 全表扫描”表锁”
- 行级锁
类型
- 共享锁S
- 读锁,可以同时被多个事务获取,阻止其他事务对记录的修改
- 排他锁X
- 写锁
- 共享锁S
所有当前读加排他锁:
数据库索引
in, not in, exists, not exists
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195➜ mysql -h 127.0.0.1 -u chyi -P 13306 -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 223
Server version: 8.0.26-0ubuntu0.20.04.2 (Ubuntu)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use develop;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> DROP TABLE IF EXISTS `t1`;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> CREATE TABLE `t1` (`id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `addreee` varchar(255) DEFAULT NULL, PRIMARY KEY(`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Query OK, 0 rows affected, 1 warning (0.06 sec)
mysql> INSERT INTO `t1` VALUES ('1001', '张三', '北京'), ('1002', '李四', '天津'), ('1003', '王五', '北京'), ('1004', '赵六', '河北'), ('1005', '杰克', '河南'), ('1006', '汤姆', '河南'), ('1007', '贝尔', '上海'), ('1008', '孙琪', '北京');
Query OK, 8 rows affected (0.04 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> select * from t1;
+------+--------+---------+
| id | name | addreee |
+------+--------+---------+
| 1001 | 张三 | 北京 |
| 1002 | 李四 | 天津 |
| 1003 | 王五 | 北京 |
| 1004 | 赵六 | 河北 |
| 1005 | 杰克 | 河南 |
| 1006 | 汤姆 | 河南 |
| 1007 | 贝尔 | 上海 |
| 1008 | 孙琪 | 北京 |
+------+--------+---------+
8 rows in set (0.04 sec)
mysql> DROP TABLE IF EXISTS `t2`;
Query OK, 0 rows affected (0.05 sec)
mysql> CREATE TABLE `t2` (`id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255), `address` varchar(255), PRIMARY KEY(`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Query OK, 0 rows affected, 1 warning (0.06 sec)
mysql> INSERT INTO `t2` VALUES (1001, '张三', '北京');
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1004, '赵六', '河北');
Query OK, 1 row affected (0.05 sec)
mysql> INSERT INTO `t2` VALUES (1005, '杰克', '河南');
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1007, '贝尔', '上海');
Query OK, 1 row affected (0.03 sec)
mysql> INSERT INTO `t2` VALUES (1008, '孙琪', '北京');
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1009, '曹操', '魏国');
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1010, '刘备', '蜀国');
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1011, '孙权', '吴国');
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1012, '诸葛亮', '蜀国');
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1013, '典韦', '魏国');
Query OK, 1 row affected (0.04 sec)
mysql> select * FROM t1 where name not in (select name from t2);
+------+--------+---------+
| id | name | addreee |
+------+--------+---------+
| 1002 | 李四 | 天津 |
| 1003 | 王五 | 北京 |
| 1006 | 汤姆 | 河南 |
+------+--------+---------+
3 rows in set (0.04 sec)
mysql> select * from t1 where not exists (select name from t2 where t1.name = t2.name);
+------+--------+---------+
| id | name | addreee |
+------+--------+---------+
| 1002 | 李四 | 天津 |
| 1003 | 王五 | 北京 |
| 1006 | 汤姆 | 河南 |
+------+--------+---------+
3 rows in set (0.04 sec)
mysql> INSERT INTO `t2` VALUES (1014, NULL, '魏国');
Query OK, 1 row affected (0.05 sec)
# not in 需要保证自查询的匹配字段是非空的
mysql> select * FROM t1 where name not in (select name from t2);
Empty set (0.04 sec)
# exists 返回的结果是一个boolean值 true或者false,而不关心某个结果集
mysql> select * from t1 where not exists (select name from t2 where t1.name = t2.name);
+------+--------+---------+
| id | name | addreee |
+------+--------+---------+
| 1002 | 李四 | 天津 |
| 1003 | 王五 | 北京 |
| 1006 | 汤姆 | 河南 |
+------+--------+---------+
3 rows in set (0.04 sec)
# 自查询中name可以修改为其他任意的字段,执行效率上1>column>*
mysql> select * from t1 where not exists (select 1 from t2 where t1.name = t2.name);
+------+--------+---------+
| id | name | addreee |
+------+--------+---------+
| 1002 | 李四 | 天津 |
| 1003 | 王五 | 北京 |
| 1006 | 汤姆 | 河南 |
+------+--------+---------+
3 rows in set (0.04 sec)
# in, exists 执行流程
# 对于in查询来说,会先执行子查询,然后把查询得到的结果和外表t1做笛卡尔,通过条件进行筛选(name是否相等)
mysql> select * from t1 where name in (select name from t2);
+------+--------+---------+
| id | name | addreee |
+------+--------+---------+
| 1001 | 张三 | 北京 |
| 1004 | 赵六 | 河北 |
| 1005 | 杰克 | 河南 |
| 1007 | 贝尔 | 上海 |
| 1008 | 孙琪 | 北京 |
+------+--------+---------+
5 rows in set (0.04 sec)
# exists,先查询便利外表t1,然后每次遍历时,在检查内标是否符合匹配条件
mysql> select * from t1 where exists (select 1 from t2 where t1.name = t2.name);
+------+--------+---------+
| id | name | addreee |
+------+--------+---------+
| 1001 | 张三 | 北京 |
| 1004 | 赵六 | 河北 |
| 1005 | 杰克 | 河南 |
| 1007 | 贝尔 | 上海 |
| 1008 | 孙琪 | 北京 |
+------+--------+---------+
5 rows in set (0.03 sec)
# 当 in 值多了之后,就不走索引了; 推测MySQL对in查询的成本优化器CBO
mysql> explain select * from t1 where id in (1001, 1002, 1003, 1004, 1005, 1006, 1007);
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 7 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.03 sec)
mysql> explain select * from t1 where id in (1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010);
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 8 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.03 sec)
# 如果查询的两个表大小相当,用in和exist差别不大,如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in.
mysql> explain select * from t1 where id in (select id from t2);
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 8 | 100.00 | NULL |
| 1 | SIMPLE | t2 | NULL | eq_ref | PRIMARY | PRIMARY | 4 | develop.t1.id | 1 | 100.00 | Using index |
+----+-------------+-------+------------+--------+---------------+---------+---------+---------------+------+----------+-------------+
2 rows in set, 1 warning (0.05 sec)
# 本意显示警告信息,但是和explain使用,会显示优化后的sql
mysql> show warnings;
+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select `develop`.`t1`.`id` AS `id`,`develop`.`t1`.`name` AS `name`,`develop`.`t1`.`addreee` AS `addreee` from `develop`.`t2` join `develop`.`t1` where (`develop`.`t2`.`id` = `develop`.`t1`.`id`) |
+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.04 sec)
# 外层大表内存小表,用in, 外层小表内层大表,in和exists效率差不多.join 嵌套循环 Nested-Loop Join
1
2
3
4
5
6
71. 简单嵌套循环连接 Simple Nested-Loop Join
inner join - 内连接 双层循环遍历两张表
一般sql中会以小表作为驱动表,外层循环,内层循环作为被驱动表
2. 索引嵌套循环连接
内存表列要有索引
3. 快索引嵌套连接 Block Nested Loop Join
> 缓存外层表的数据到join buffer中,然后buffer中数据批量和内层表数据进行匹配,从而减少内存循环的次数